Ads block

Sơ đồ nối đất

1. Sơ đồ TT: Trung tính-đất, vỏ kim loại-đất (vỏ kim loại nối thẳng xuống đất): nó thích hợp cho lưới có sự kiểm tra hạn chế or lưới có thể mở rộng hoặ…
Đọc thêm »
Đường cong ROC - receiver operating characteristic
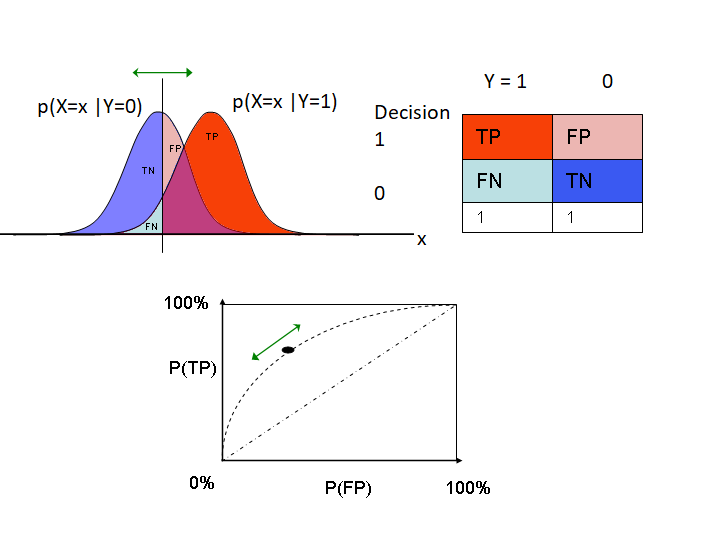
Trong lý thuyết phát hiện tín hiệu , một receiver operating characteristic ( ROC ), còn gọi là receiver operating curve (đường cong đặc trưng hoạt động c…
Đọc thêm »
Tổng quan về Mạng Neuron (Neural Network)

Mạng Neuron nhân tạo (Artificial Neural Network- ANN) là mô hình xử lý thông tin được mô phỏng dựa trên hoạt động của hệ thống thần kinh của sinh vật, bao gồ…
Đọc thêm »
Blogroll
Section Background

Background image. Ideal width 1600px with.
Section Background

Background image. Ideal width 1600px with.
Logo
Logo Image. Ideal width 300px.
Header Background

Header Background Image. Ideal width 1600px with.
Section Background

Bài đăng phổ biến
-
 Con trỏ chuột trong vùng đồ họa của AutoCAD bao gồm 2 phần: Crosshair và Pickbox. Theo mặc định trong AutoCAD, Crosshair là hai đường th...
Con trỏ chuột trong vùng đồ họa của AutoCAD bao gồm 2 phần: Crosshair và Pickbox. Theo mặc định trong AutoCAD, Crosshair là hai đường th... -
 Thư viện CAD tủ điện cung cấp bản vẽ các thiết bị thông dụng sử dụng trong tủ điện như MCCB, MCB, Contator, Relay... Link download: https:/...
Thư viện CAD tủ điện cung cấp bản vẽ các thiết bị thông dụng sử dụng trong tủ điện như MCCB, MCB, Contator, Relay... Link download: https:/... -
 FCO - Fuse Cutout hay Cut-out fuse - là thiết bị bảo vệ cho mạng trung thế, được phối hợp giữa một cầu chì và dao cắt, được sử dụng ở...
FCO - Fuse Cutout hay Cut-out fuse - là thiết bị bảo vệ cho mạng trung thế, được phối hợp giữa một cầu chì và dao cắt, được sử dụng ở...


